Aiffel_learning/Data_analysis
2-6. pandas : outlier
이유29
2024. 6. 6. 21:55
outlier(아웃라이어) 이란?
데이터 분석에서 다른 데이터 포인트들과 크게 다르거나 이질적인 값.
아웃라이어는 통계 분석, 데이터 분석, 머신 러닝 모델링 등에 있어서
데이터의 패턴을 왜곡시키거나 잘못된 결론을 내리게 할 수 있기 때문에 중요한 역할을 함
왜 생기는걸까?
- 데이터 입력 오류: 데이터 입력 중의 실수나 잘못된 기록으로 인해 발생
- 실험적 오류: 실험 과정에서의 오류나 장비의 결함으로 인해 발생
- 자연적인 변동성: 데이터 자체의 본질적인 변동성 때문에 발생
- 분포 특성: 특정 분포의 특성으로 인해 극단적인 값이 존재
그럼 어떻게 알아?
- 시각적 방법:
- 박스 플롯(Box Plot): 박스 플롯에서 상자 밖에 위치하는 점들은 아웃라이어로 간주
- 산점도(Scatter Plot): 2차원 산점도에서 다른 점들과 멀리 떨어져 있는 점들을 아웃라이어로 식별
- 통계적 방법:
- Z-점수(Z-score): 각 데이터 포인트의 평균으로부터의 표준편차 거리를 계산하여 일정 기준 이상 떨어져 있는 값들을 아웃라이어로 간주
- 사분위수 범위(IQR): 1사분위수(Q1)와 3사분위수(Q3)의 차이인 IQR을 이용하여, Q1 - 1.5IQR 보다 작거나 Q3 + 1.5IQR 보다 큰 값들을 아웃라이어로 간주
- 머신 러닝 방법:
- Isolation Forest: 데이터의 하위 집합을 무작위로 선택하고 이들을 반복적으로 분할하여 아웃라이어를 탐지
- LOF(Local Outlier Factor): 데이터 포인트가 주변 데이터 포인트들과 비교하여 얼마나 밀집된 곳에 위치하는지를 측정하여 아웃라이어를 탐지
- 이상, 챗지피티의 설명이었다.
그럼 pandas에서는 어떻게 아웃라이어를 찾아내고 처리할까?
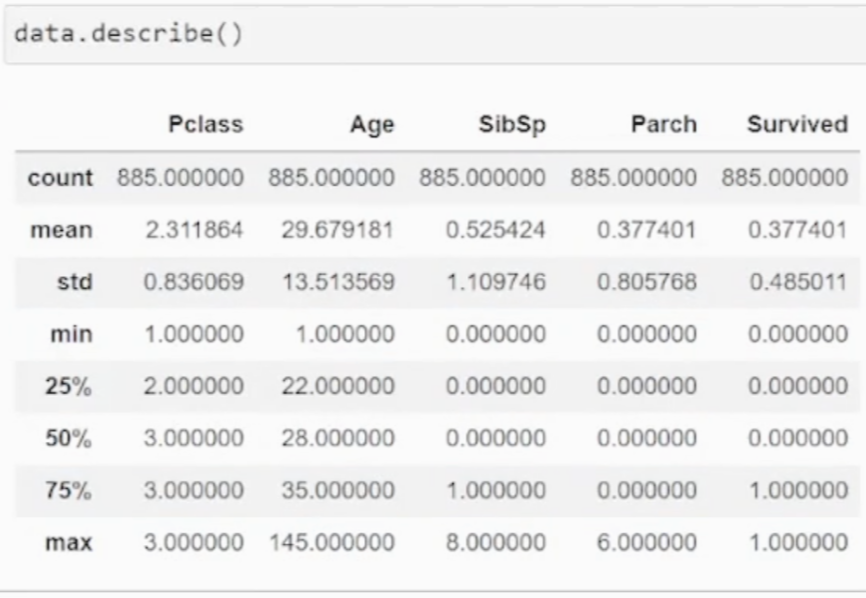
outlier가 존재하는가?
보통 min ~ max 값 까지의 분포를 보면서 파악
데이터 분석적 사고로 상식적으로 말이 안되는 부분 확인
[Age] 나이가 145... 말이 안됨
[SibSp] 50%R까지 0명이다가 max가 8
문제가 있을것 같은 부분 찾았으니 확인해보도록 하자.
일단, 오름차순으로 정렬하면
# 오름차순
data.sort_values()
# 내림차순
data.sort_values(ascending = False)| Age | SibSp |
 |
 |
| 8 값이 생각보다 많네? 그럼 뒷 부분만 좀 뜯어볼까? |
|
 |
|
| 145 값이 outlier인것 확인! -> 이건 값 지우자 97, 80은 고민을 좀 해봐야할듯 |
오,,,,분포를 잘 모르겠군 -> 그래프로 확인해보자! |
분포 확인하는 그래프 출력해서 확인하기
import matplotlib.pyplot as plt
import seaborn as snsdistribution 확인
- displot : 데이터 분포를 시각화하는 Seaborn의 플롯 (현재는 histplot이나 kdeplot 사용 권장).
- scatterplot : 두 변수 간의 관계를 시각화하는 산점도 * 좀 더 직관적이고, 튀는값 여부 확인가능*
- boxplot : 데이터의 분포와 사분위수, 이상치를 나타내는 상자 그림.
| tool | Age | SigSp |
| sns.displot() |  |
 |
| 몇개 없는 값들은 눈에 잘 띄지 않아서 쓰기 불편해 |
오, 8도 숫자가 꽤 있는걸 보니 그렇게 특이한 케이스는 아니고 있을 수는 있는 값인가 보다?! 확인가능 |
|
| sns.scatterplot() |  |
 |
| 140 값은 진짜 말도 안되는 outlier인것 보임 100은 조금 애매 |
8 값이 outlier은 아닌것 확정 | |
| sns.boxplot() | 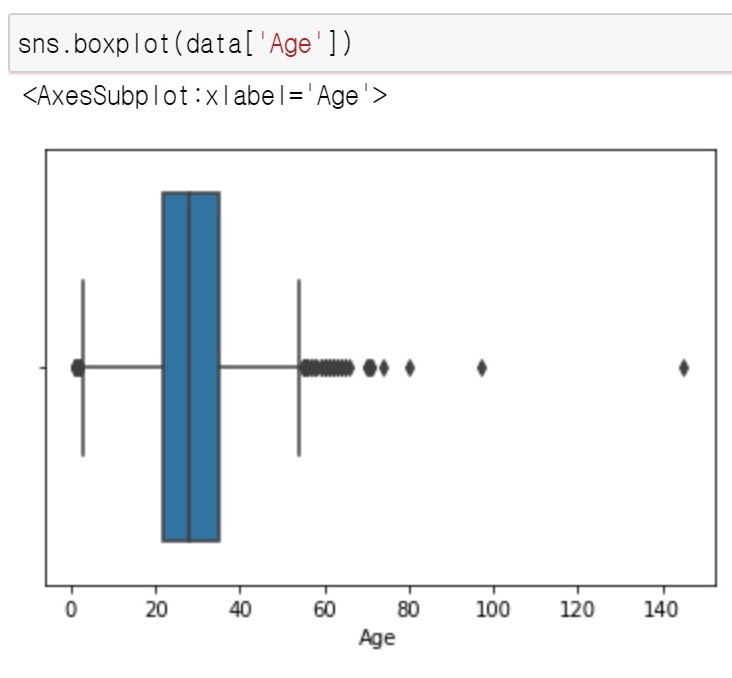 |
 |
| 파란 박스부분 = 25~75% 분포부분 까만 선(파란박스 길이의 1.5배만큼 양쪽으로 뻗은 값)을 그어서 이 바깥은 outlier이다 나름대로 판단해줌 (그치만 참고만 하기.. 좀 너무 극단적이라..!) |
||
outlier 제거하기
# 1. 일정 값 이하만 출력하기
data = data[data['Age'] <= 100
# 2. 일정 값 이상을 고정하기
# 계속 사용할 것 같으면 함수생성
def age_func(x):
if x > 80:
return 80
else:
return x
# age_func(data['Age']) 하면 에러남!
data['Age'] = data['Age'].apply(age_func)
# lambda 써도 되는데 이건 일회용일떄!
data['Age'].apply(lambda x: 80 if x > 80 else x)
참고하면 좋을것 같은 블로그**
https://sjquant.tistory.com/17
[요약] 데이터 아웃라이어 처리하기
How to Deal with Outliers in Your Data 내용을 한글로 정리해 보았습니다. 아웃라이어란? 아웃라이어란 데이터 상의 다른 값들의 분포와 비교했을때 비정상적으로 떨어져있는 관측치이다. 하지만, 어느
sjquant.tistory.com